June 3, 2026
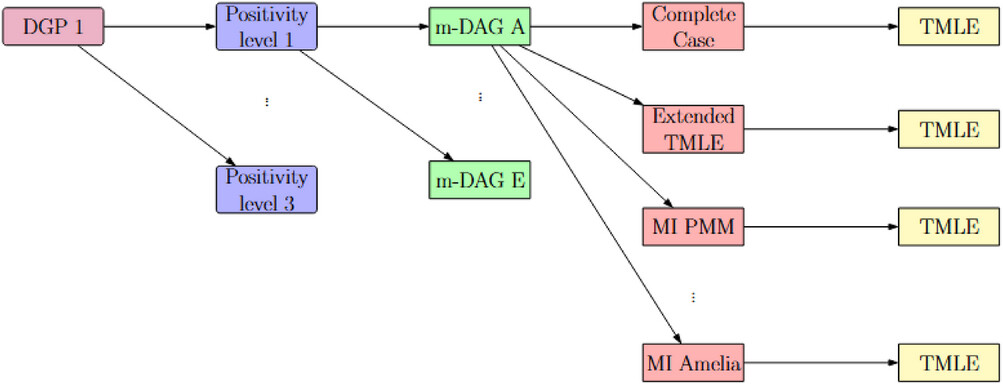
The authors evaluated the performance of targeted maximum likelihood estimation (TMLE) for estimating the average treatment effect in missing data scenarios under varying levels of positivity violations. Directed acyclic graphs (DAGs) have been used in causal inference. They have also been extended to show missingness mechanisms (m-DAG). Since under causal inference, the average treatment effect (ATE) is a key target parameter, targeted maximum likelihood estimation (TMLE) is often used to estimate the ATE because of its robust properties. The TMLE is also a plug-in-estimator, which means that while it directly targets the parameter of interest, it also allows for incorporation of data-adaptive methods like machine learning methods. Also, positivity is a crucial assumption in causal inference and requires that within each stratum of the confounders, every individual has a nonzero probability of receiving either exposure condition.
The m-DAGs include missingness indicators which encode assumptions about the processes leading to missing data. Recoverability refers to ability to consistently estimate a target parameter, like an ATE, from the available data even in presence of missing data. There are many ways to handle missing data and many assumptions. The non-multiple imputation (MI) strategies they considered were: complete-case analysis, extended TMLE (discards observations with missing values in confounders and exposure variables and then incorporates a model for outcome missingness into the targeting step of the TMLE; Ext), and extended TMLE with missing covariate missing indicator (ext MCMI), where only observations with missing exposure data are excluded and missingness indicators are included for incomplete confounders. Another option, fully conditional specification (FCS) Methods, which are chained equation approaches and implemented in the mice package in R, iteratively imputes missing values by sampling from a series of univariate conditional models. The possible methods are: MI using predictive mean matching (MI PMM), which uses parametric imputation using PMM for the outcome and applies appropriate models for other variables based on their type of outcome, MI with interaction terms (MI Int), MI using classification and regression trees (MI CART), and MI using Random Forest (MI RF). Finally, a last approach is MI using Amelia, which assumes that the hypothetically complete data follow a multivariate normal distribution and uses the Amelia package in R.
They then ran simulations with 5 distinct (data generating processes) DGPs, each with 3 scenarios varying in positivity violation severity. In the 5th DGP, a gamma-distributed confounder was additionally included. They had to setup quantifying positivity violations in the data using propensity score estimation and then using the estimated score as well as one minus that to detect a minimum of either to be below 0.0002. Missingness was generated by imposing missingness indicators which was 1 if the variable was missing or 0 if observed. To validate the results of the model-based simulation study, they applied the under smoothed HAL approach following Li et al. (2022). HAL captured a realistic confounding structure where HAL is a nonparametric regression estimator designed to estimate complex functional parameters with minimal assumptions about the underlying data distribution.
The results of model- based simulations showed that non-MI methods, CC and Ext, exhibited performed fairly similar to each other. The Ext MCMI performed almost worse across all m-DAGs, DGPs, and positivity scenarios compared to CC and Ext. The parametric MI approaches, MI PMM and MI Int, often resulted in greater bias across all m-DAGs and DGPs compared to the non-MI methods CC and Ext. The performance of MI-CART was more dependent upon the underlying DGP than on the specific missingness mechanism. MI Amelia exhibited small bias across m-DAGs A, B, and C in scenario 1 for DGPs 2 and 3.
The results of the design-based simulations showed that non-MI methods, CC and Ext, exhibited extremely low bias across m-DAGs. the third non-MI method, Ext-MCMI, performed similarly to CC and Ext across all m-DAGs. The Ext method was superior to both other non-MI methods across all m-DAGs. The parametric MI approaches, MI-PMM and MI-Int, exhibited slightly greater bias across the m-DAGs where the ATE was recoverable, compared with the non-MI methods (CC and Ext). The nonparametric MI methods (MI RF and MI CART) performed similarly across the missingness scenarios. Both exhibited higher bias in m-DAGs A, B, and C but showed markedly lower bias under m-DAGs D and E. Meanwhile, MI CART was substantially superior to MI RF and yielded approximately unbiased estimates for the ATE in m-DAGs D and E.MI Amelia also showed smaller bias in m-DAGs D and E and larger bias in m-DAGs A, B, and C.
In terms of RMSE results, the nonparametric MI methods (MI RF and MI CART) generally exhibited the lowest RMSE in both the model-based and design-based simulations across all settings. In contrast, MI Amelia achieved comparable RMSE in the design-based simulation and showed lower RMSE in DGPs 2 and 3 of the model-based simulation, largely due to its lower bias. The parametric MI methods, MI PMM and MI Int, showed substantially higher RMSE in positivity level 2 and 3 of the model-based simulation due to high bias and performed comparably to the nonparametric methods in the design-based setting, although still slightly worse. The MI Int generally exhibited higher RMSE than MI PMM. Among the non-MI methods, Ext and CC had similar RMSE across both simulation types, while Ext-MCMI matched their performance in the design-based simulation but performed slightly better in the model-based simulation under severe positivity violations.
In terms of coverage probabilities, in both the model- and design-based simulations, MI CART and MI RF exhibited overcoverage, with MI CART generally being closer to the nominal 95% coverage rate. The non-MI methods systematically led to undercoverage in both simulation types, with pronounced undercoverage in the model-based simulation under severe positivity violations.
In summary, Ext, which incorporates an outcome-missingness model within TMLE, emerged as the most robust approach under the three non-MI methods for unbiased ATE estimation across both simulation types. Non-MI methods exhibited poor nominal coverage under severe positivity violations. Under increasing positivity violation, CC and Ext generally exhibited less bias than MI approaches, whereas MI methods tended to be closer to the nominal coverage rate, reflecting a bias–coverage trade-off. Among MI strategies, MI CART provided the most reliable interval coverage and smallest RMSE, including in non-recoverable settings with severe violation. Overall, method choice should depend on recoverability and the severity of positivity violations, balancing bias, coverage, and precision.
Written by,
Usha Govindarajulu
Keywords: causal inference, TMLE, missing data, positivity
References:
Li, H., S. Rosete, J. Coyle, et al. 2022. “Evaluating the Robustness of Targeted Maximum Likelihood Estimators via Realistic Simulations in Nutrition Intervention Trials.” Statistics in Medicine 41, no. 12: 2132–2165.
Wiederkehr C, Heumann C, and Schomaker M (2026) “Causal Effect Estimation with TMLE: Handling Missing Data and Near Violations of Positivity” Biometrical Journal,
https://doi.org/10.1002/bimj.70134
https://onlinelibrary.wiley.com/cms/asset/c8154fcb-df09-4dcb-9454-264a8f7d9b72/bimj70134-fig-0002-m.jpg